
2026年3月6日,OpenAI正式发布了其最新的旗舰模型。 GPT-5.4该模型定位为专业级工作系统,其核心逻辑在于将推理、编程和智能体工作流程整合到一个统一的生产力框架中。此次更新标志着人工智能从对话工具向具备执行能力的自主系统转变。
GPT-5.4 的核心技术升级
本地计算机使用和 OpenClaw 趋势
GPT-5.4 引入了原生计算机使用功能。该模型现在可以从屏幕截图中解析屏幕坐标,并直接发出鼠标和键盘命令。此次升级正式确立了“OpenClaw”(开放代理控制)方法,使人工智能能够跨多个应用程序执行连续任务。
技术实施细节: 此功能并非直接在物理硬件上运行,而是需要在受控的执行环境中运行,例如 剧作家 或者 Docker 作为交互媒介。在企业生产环境中,这需要特定的基础设施配置,而不是简单的 API 调用。
推理计划预览
在交互层面,GPT-5.4 新增了“推理计划预览”功能。在生成最终答案之前,模型会展示其思考步骤和执行逻辑。用户可以在生成过程中输入指令来调整计划方向,从而提高复杂任务的成功率。
表演前提条件: OpenAI发布的一些顶级性能数据是使用以下方法测试的: “xhigh”推理模式在标准生产环境中,解决极其复杂的问题时,默认推理强度可能与演示数据存在差距。
百万级上下文窗口和令牌计费逻辑
GPT-5.4 支持长达 10 ... 105万枚代币 它适用于 Codex 和特定的 API 环境。它旨在处理海量代码库或完整的行业文档集。
账单提醒:
- 配置要求105万代币容量是Codex中的一项实验性功能,需要手动配置。
- 分级计费使用量超过 27.2万个代币 账单金额为 双倍的 基本费率意味着处理超长文本的边际成本大幅增加。
统一推理与编程系统
该版本整合了以下方面的编程专业知识: GPT-5.3-Codex该模型消除了通用编程模型和专用编程模型之间的界限。它能够同时调用逻辑推理和代码生成功能,并通过全新的 Playwright 技能实现自动化开发和调试的闭环。
ChatGPT-5.4 基准性能分析
OpenAI发布的测试数据显示,GPT-5.4在多个方面已经接近或超越了人类的基准:
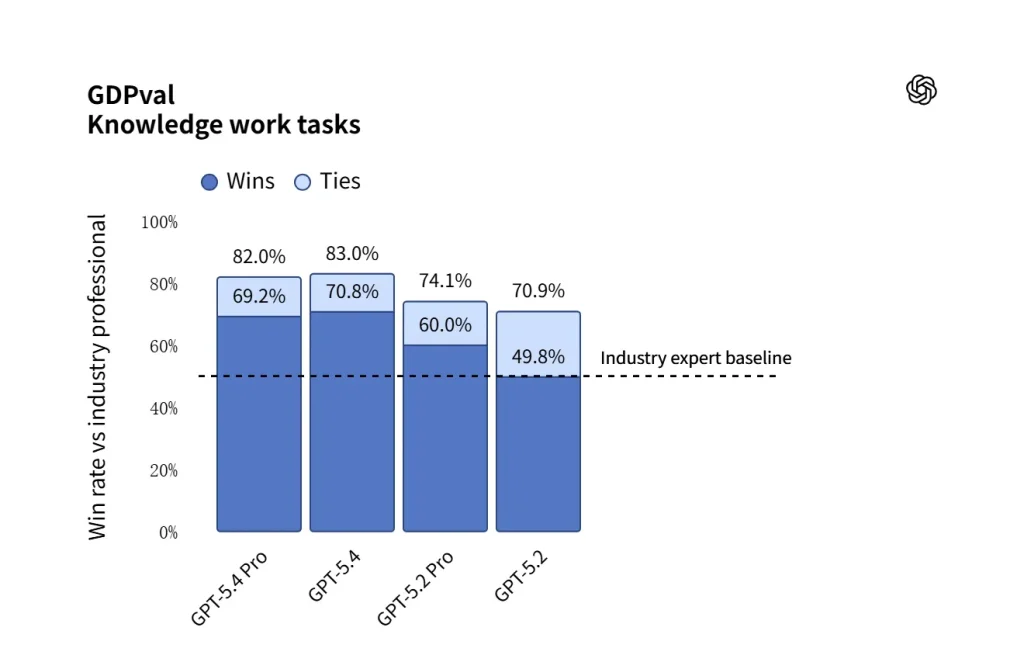
- GDPval(专业任务测试)在 44 个职业场景中,GPT-5.4 的表现达到或超过了人类专业人员的水平。 83% 任务。
- OSWorld(桌面控制测试)在通过屏幕截图控制桌面的测试中,成功率达到了 75%超越了人类的基准线 72.4% 首次。
- 幻觉控制OpenAI指出,幻觉发生率是 33% 下部 与 5.2 版本相比,绝对错误率并未公开,第三方评估显示,不同垂直领域的准确性改进程度各不相同。
GPT-5.4 与核心竞争对手(例如 Claude Opus 4.6)的比较
| 评估维度 | GPT-5.4(思考) | GPT-5.3(Codex) | 克劳德作品 4.6 |
| 本地计算机使用成功率 | 75% | / | 72.70% |
| 专业任务(GDPval) | 83% | 70.90% | 76.50% |
| 标准上下文窗口 | 1.05M(实验) | 272K | 20万 |
| 推理模式调整 | 支持 | 不支持。 | 不支持。 |
| 编程(SWE-bench) | 57.70% | 56.80% | 51.20% |
真实用户评论:生产力转折点
马特·舒默HyperWriteAI 和 OthersideAI 的首席执行官在经过深入测试后,对 GPT-5.4 给予了高度评价。他指出了 GPT-5.4 在生产环境中的几个优势:
- 更高的“氛围编码”上限该模型显著提高了非精确指令下的代码生成质量。对于复杂的机器学习任务,例如调整数据管道,其可靠性已达到可交付水平。
- 工作流程连续性由于响应速度得到优化,该模型在长逻辑链中保持低延迟,从而减轻了开发人员的认知负担。
- 文件关联准确率处理大型项目文件关联时,上下文保留更加稳定,减少了交叉文件引用中的逻辑错误。
舒默指出,GPT-5.4 代表着“高强度生产力”首次大规模应用于专业工作者。对于市场营销、销售和营收运营等行业的专业人士而言,核心差距将不再是基本的软件技能,而是人工智能工具的利用效率以及基于方法论的决策能力。
专业人士应如何适应 GPT-5.4
随着 GPT-5.4 获得直接执行任务的能力,专业人士必须从“执行者”转变为“战略管理者”:
- 测试工作流程自动化利用计算机原生功能或简化的工作流程工具(例如 iWeaver将重复性的行政或数据任务转化为自动化流程。
- 加强需求阐述人工智能执行能力的上限取决于用户准确描述需求的能力。诸如此类的工具 iWeaver 提示符优化器 将成为提高产品质量的关键因素。
- 提升决策能力和审美由于人工智能可以生成大量的解决方案,人类的价值在于运用商业经验和审美来判断哪个解决方案最符合实际的业务需求。

