
Qwen3.6-Plus è l'ultimo modello di punta bilanciato di Alibaba Cloud in Model Studio, in arrivo poco dopo Reuters È stato riportato che Junyang Lin, leader di Qwen, si è dimesso. La documentazione attuale di Alibaba Cloud elenca una finestra di contesto di 1.000.000 di token, la modalità di ragionamento misto attivata di default, l'input multimodale e un prezzo che parte da 2 RMB per milione di token di input nella Cina continentale per richieste fino a 256.000 token di input.
Caratteristiche e benchmark di Qwen3.6-Plus
Modalità contesto lungo, prezzi e ragionamento
Alibaba Cloud presenta Qwen3.6-Plus come un modello di punta che bilancia qualità, velocità e costi. Nella documentazione ufficiale del modello, la versione stabile è elencata con una finestra di contesto di 1.000.000 di token, fino a 65.536 token di output e una lunghezza massima di pensiero di 81.920 token in modalità di pensiero; la stessa documentazione mostra anche che la modalità di pensiero è abilitata per impostazione predefinita.
La stessa documentazione mostra che Qwen3.6-Plus supporta testo, immagini e video L'input è importante perché sposta il modello oltre la semplice generazione di testo, verso un'analisi multimodale. Questo lo rende più rilevante per flussi di lavoro come la comprensione dell'interfaccia utente, l'analisi sintattica dei documenti e il ragionamento multimediale, non solo per le chat standard o il completamento del codice.
Codifica e posizionamento multimodale
La documentazione del prodotto di Alibaba descrive Qwen3.6-Plus come un sistema potente in diverse aree, tra cui la comprensione del linguaggio, il ragionamento logico, la generazione di codice, le attività degli agenti, la comprensione delle immagini, la comprensione dei video e le attività dell'interfaccia utente. Anche la pagina di lancio ufficiale di Qwen presenta il modello come un sistema in grado di migliorare gli agenti di programmazione, gli agenti generici e l'utilizzo degli strumenti grazie a una maggiore integrazione tra ragionamento, memoria e interazione con gli strumenti.
Tale posizionamento suggerisce un modello orientato all'esecuzione pratica piuttosto che a semplici dimostrazioni di risposta immediata. In termini editoriali, è più corretto descrivere Qwen3.6-Plus come un modello di programmazione e agente ospitato, piuttosto che come un chatbot generico con una modalità di programmazione aggiunta.
Come leggere i risultati del benchmark
Il lancio di Alibaba rapporto sui materiali I risultati pubblicati dal fornitore includono un punteggio di 78,8 su SWE-bench Verified e di 61,6 su Terminal-Bench 2.0. Gli stessi materiali di lancio evidenziano anche i miglioramenti ottenuti in valutazioni più ampie su agenti reali e sistemi multimodali, quindi l'azienda presenta chiaramente Qwen3.6-Plus come un modello ottimizzato per flussi di lavoro ad alta intensità di esecuzione piuttosto che per attività ristrette a singolo turno.
Alcuni utenti hanno anche messo in discussione la scelta dei target di confronto, chiedendo perché Qwen3.6-Plus non sia stato confrontato direttamente con Claude Opus 4.6 O Gemini 3.1 Pro. Una spiegazione più probabile è il posizionamento del prodotto. Qwen3.6-Plus appartiene alla serie Plus, progettata per un utilizzo ad alta concorrenza, quindi il suo set di confronto è più vicino a modelli come Claude 4.5 Opus in termini di scenari di implementazione e livello di consumo di risorse di calcolo. Da questo punto di vista, i benchmark selezionati sembrano riflettere un allineamento pratico del prodotto piuttosto che puntare semplicemente ai nomi dei modelli più recenti.
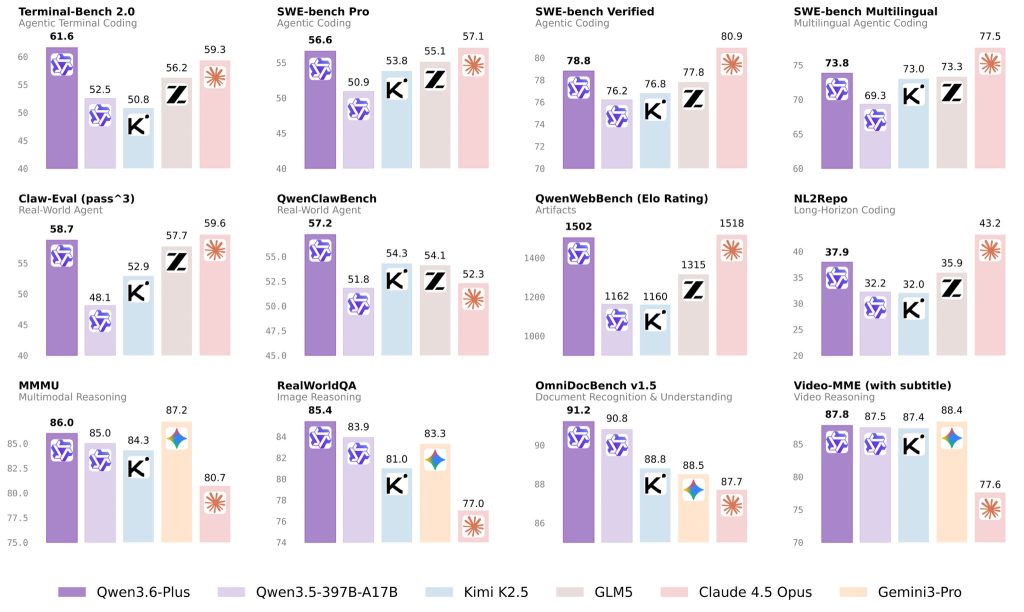
Questi numeri risultano più utili se abbinati alle definizioni originali dei benchmark. SWE-bench valuta se un modello o un agente è in grado di risolvere problemi reali di GitHub all'interno di repository reali; SWE-bench Verified è un sottoinsieme di 500 attività filtrate manualmente; Terminal-Bench 2.0 misura le prestazioni su 89 attività complesse da terminale ispirate a flussi di lavoro reali; e OmniDocBench valuta l'analisi di diversi file PDF provenienti da nove fonti di documenti con annotazioni dettagliate di layout e attributi.
| Segno di riferimento | Cosa misura | Perché è importante |
| SWE-bench verificato | Risoluzione di problemi software reali nei codebase | Utile per valutare il debug a livello di repository e la generazione di patch |
| Terminal-Bench 2.0 | Esecuzione di attività da riga di comando in più fasi | Utile per l'automazione dei terminali, i flussi di configurazione e l'affidabilità degli agenti. |
| OmniDocBench | Analisi complessa di PDF e documenti | Utile per documenti tecnici, specifiche, tabelle e formule. |
| Valutazioni di agenti nel mondo reale | Pianificazione in più fasi e utilizzo di strumenti | Utile per il completamento dell'intero flusso di lavoro, piuttosto che per risposte isolate. |
Un esempio pratico è un'attività di ingegneria a lungo termine in cui il modello deve leggere un archivio di grandi dimensioni, identificare i file rilevanti, pianificare una soluzione, eseguire azioni terminali e verificarne il risultato. Un altro esempio è l'analisi di lunghi PDF tecnici o documenti ricchi di immagini prima di convertirli in riassunti, note di implementazione o attività successive.
Di cosa si sta discutendo riguardo a Qwen3.6-Plus?
La tempistica di questa uscita è significativa perché è arrivata poco dopo il cambio di leadership annunciato all'interno del team Qwen. Questo contesto, di per sé, non dimostra una rottura strategica, ma aiuta a spiegare perché il lancio abbia attirato l'attenzione ben oltre le sole specifiche del modello. In pratica, molti lettori stanno valutando sia il prodotto in sé sia ciò che potrebbe indicare in merito alla prossima fase di Qwen.
Durante la revisione discussioni degli sviluppatori Nelle varie comunità tecniche, ho notato che l'attenzione principale non era rivolta esclusivamente ai punteggi dei benchmark. Piuttosto, gran parte dell'attenzione si concentrava sul fatto che Qwen3.6-Plus è attualmente rilasciato in una versione closed-source ospitata su server esterni, con accesso limitato alle chiamate API e all'anteprima della piattaforma.
Questa reazione è comprensibile. Le precedenti versioni di Qwen si erano guadagnate una solida reputazione tra gli sviluppatori grazie a un approccio più aperto, quindi questo nuovo rilascio ha innescato un dibattito su cosa questo cambiamento possa significare in pratica.
La prima preoccupazione riguarda l'implementazione locale e la privacy dei dati. Molti utenti aziendali si affidano a modelli aperti per la messa a punto on-premise e l'implementazione privata al fine di soddisfare rigorosi requisiti di conformità e sicurezza. Un modello chiuso, basato su API, implica che codebase, documenti o dati aziendali debbano essere elaborati tramite il cloud, il che può rendere più difficile l'adozione in settori sensibili alla privacy come quello finanziario e sanitario.
La seconda preoccupazione riguarda la velocità di adattamento dell'ecosistema e della toolchain. I modelli aperti tendono a generare molto rapidamente plugin della community, varianti quantizzate, flussi di lavoro di ottimizzazione e utility di terze parti. Se la linea principale di Qwen 3.6 rimane chiusa, alcuni sviluppatori potrebbero essere meno propensi a investire nella creazione di strumenti esterni e integrazioni.
Una terza interpretazione è più commerciale che tecnica. Alcuni osservatori del settore vedono in questo un possibile segnale della più ampia strategia di monetizzazione di Alibaba Cloud: mantenere i suoi modelli più performanti all'interno della propria piattaforma cloud al fine di rafforzare l'adozione dei servizi gestiti, l'utilizzo delle API e i relativi ricavi derivanti dalle risorse di calcolo.
Nel complesso, ciò non indebolisce necessariamente il prodotto in sé. Tuttavia, modifica i compromessi. Per i team che già operano all'interno di Alibaba Cloud, il modello hosted può risultare conveniente ed economicamente vantaggioso. Per i team che danno priorità all'hosting autonomo, alla governance o a una personalizzazione approfondita, il modello di implementazione può essere quasi altrettanto importante quanto i risultati dei benchmark.
Qwen3.6-Plus Sembra un'opzione di hosting seria per gli sviluppatori che tengono conto del contesto a lungo termine, dei flussi di lavoro di programmazione e delle attività multimodali degli agenti. Le sue specifiche ufficiali sono solide, il prezzo è relativamente competitivo nella fascia bassa e i materiali di lancio di Alibaba lo posizionano in modo credibile nelle categorie di benchmark ad alta intensità di esecuzione, ma il lancio in hosting potrebbe comunque essere una considerazione importante per i team che preferiscono modelli open-weight o self-hosted.

