
Qwen3.6-Plus est le dernier modèle phare équilibré d'Alibaba Cloud dans Model Studio, disponible peu après Reuters Il a été rapporté que Junyang Lin, dirigeant de Qwen, avait démissionné. La documentation actuelle d'Alibaba Cloud mentionne une fenêtre de contexte d'un million de jetons, un mode de raisonnement mixte activé par défaut, une entrée multimodale et une tarification débutant à 2 RMB par million de jetons d'entrée en Chine continentale pour les requêtes allant jusqu'à 256 000 jetons d'entrée.
Caractéristiques et performances de Qwen3.6-Plus
Mode de contexte, de tarification et de raisonnement long
Alibaba Cloud présente Qwen3.6-Plus comme un modèle phare offrant un équilibre optimal entre qualité, vitesse et coût. La documentation officielle du modèle indique que la version stable dispose d'une fenêtre de contexte d'un million de jetons, d'un maximum de 65 536 jetons de sortie et d'une longueur de réflexion maximale de 81 920 jetons en mode « réflexion ». Cette même documentation précise également que le mode « réflexion » est activé par défaut.
La même documentation indique que Qwen3.6-Plus prend en charge texte, image et vidéo L'entrée est importante car elle permet au modèle de dépasser la simple génération de texte pour s'orienter vers une analyse multimodale. Cela le rend plus pertinent pour des flux de travail tels que la compréhension d'interfaces graphiques, l'analyse syntaxique de documents et le raisonnement multimédia, et pas seulement pour les conversations standard ou la saisie semi-automatique de code.
Codage et positionnement multimodal
La documentation produit d'Alibaba décrit Qwen 3.6 Plus comme performant en compréhension du langage, raisonnement logique, génération de code, tâches d'agents, compréhension d'images et de vidéos, et tâches d'interface graphique. La page de lancement officielle de Qwen présente également le modèle comme améliorant les agents de programmation, les agents généraux et l'utilisation des outils grâce à une intégration plus poussée du raisonnement, de la mémoire et de l'interaction avec les outils.
Ce positionnement suggère un modèle axé sur une mise en œuvre pratique plutôt que sur de simples démonstrations de réponses instantanées. D'un point de vue éditorial, il est plus juste de décrire Qwen3.6-Plus comme un modèle de programmation hébergée et intégrant un agent, plutôt que comme un chatbot généraliste auquel on aurait ajouté un mode de programmation.
Comment interpréter les résultats de l'analyse comparative
Lancement d'Alibaba rapport sur les matériaux Les résultats publiés par le fournisseur incluent un score de 78,8 sur SWE-bench Verified et de 61,6 sur Terminal-Bench 2.0. Les mêmes documents de lancement mettent également en avant les gains obtenus lors d'évaluations plus larges d'agents et de systèmes multimodaux en conditions réelles. L'entreprise présente donc clairement Qwen3.6-Plus comme un modèle optimisé pour les flux de travail complexes plutôt que pour des tâches ponctuelles et limitées.
Certains utilisateurs ont également remis en question le choix des cibles de comparaison, se demandant pourquoi Qwen3.6-Plus n'avait pas été testé directement par rapport à Claude Opus 4.6 ou Gemini 3.1 ProUne explication plus probable réside dans le positionnement du produit. Qwen3.6-Plus appartient à la série Plus, conçue pour une utilisation intensive simultanée ; son ensemble de comparaison est donc plus proche de modèles tels que… Claude 4.5 Opus En termes de scénarios de déploiement et de niveau de consommation de calcul, les benchmarks sélectionnés semblent refléter une adéquation pratique des produits plutôt que de simplement viser les noms de modèles les plus récents.
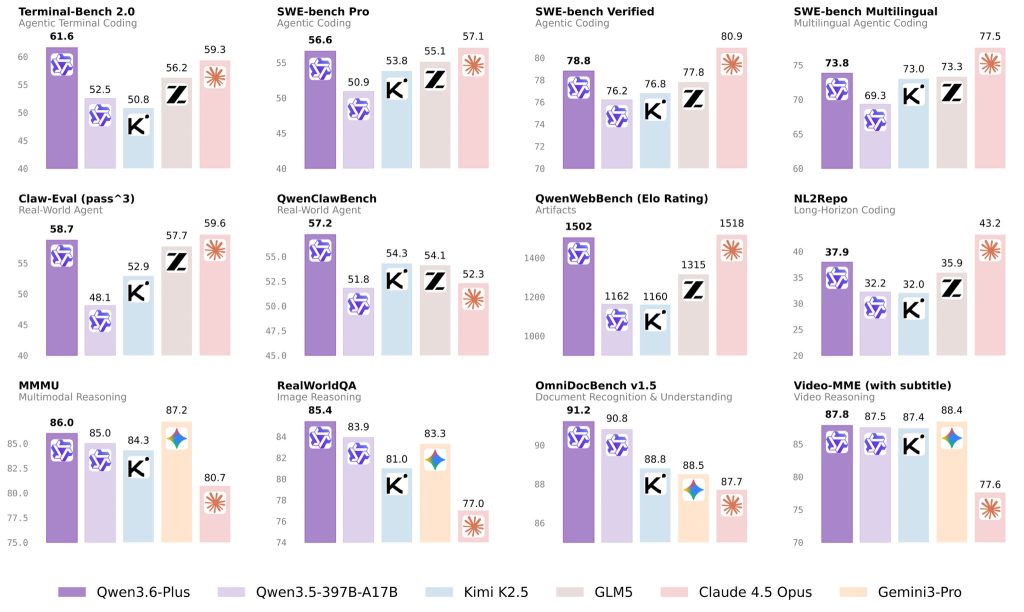
Ces chiffres sont plus pertinents lorsqu'ils sont associés aux définitions de référence d'origine. SWE-bench évalue la capacité d'un modèle ou d'un agent à résoudre des problèmes GitHub réels au sein de dépôts existants ; SWE-bench Verified est un sous-ensemble de 500 tâches filtrées manuellement ; Terminal-Bench 2.0 mesure les performances sur 89 tâches de terminal inspirées de flux de travail réels ; et OmniDocBench évalue l'analyse syntaxique de divers fichiers PDF à partir de neuf sources de documents avec des annotations précises de mise en page et d'attributs.
| Référence | Ce que cela mesure | Pourquoi c'est important |
| Vérifié par SWE-bench | Résolution réelle des problèmes logiciels dans les bases de code | Utile pour évaluer le débogage au niveau du dépôt et la génération de correctifs |
| Terminal-Bench 2.0 | Exécution de tâches en ligne de commande en plusieurs étapes | Utile pour l'automatisation des terminaux, les flux de configuration et la fiabilité des agents |
| OmniDocBench | Analyse complexe de PDF et de documents | Utile pour les documents techniques, les spécifications, les tableaux et les formules. |
| Évaluations d'agents dans le monde réel | Planification en plusieurs étapes et utilisation des outils | Utile pour la réalisation complète d'un flux de travail de bout en bout plutôt que pour des réponses isolées. |
Un exemple concret est celui d'une tâche d'ingénierie à contexte long où le modèle doit lire un vaste référentiel, identifier les fichiers pertinents, planifier une correction, exécuter des actions terminales et vérifier le résultat. Un autre exemple est l'analyse de longs fichiers PDF techniques ou de documents riches en images avant leur conversion en résumés, notes d'implémentation ou tâches en aval.
Que dit Qwen3.6-Plus ?
Le moment choisi pour cette sortie est important car elle intervient peu après le changement de direction annoncé au sein de l'équipe Qwen. Ce contexte ne prouve pas à lui seul une rupture stratégique, mais il contribue à expliquer pourquoi ce lancement a suscité un tel intérêt, au-delà des seules spécifications techniques. En pratique, de nombreux lecteurs évaluent à la fois le produit lui-même et ce qu'il pourrait révéler quant à la prochaine étape de Qwen.
Lors de l'examen discussions entre développeurs Au sein des communautés techniques, j'ai constaté que l'attention ne se portait pas uniquement sur les scores de référence. En effet, le fait que Qwen 3.6 Plus soit actuellement distribué sous forme hébergée et à code source fermé, avec un accès limité aux appels d'API et à la préversion de la plateforme, était largement préoccupant.
Cette réaction est compréhensible. Les versions précédentes de Qwen avaient suscité un fort engouement auprès des développeurs grâce à une approche plus ouverte ; ce déploiement a donc ouvert le débat sur les implications concrètes de ce changement.
La première préoccupation concerne le déploiement local et la confidentialité des données. De nombreuses entreprises privilégient les modèles ouverts pour le paramétrage précis sur site et le déploiement privé afin de répondre à des exigences strictes de conformité et de sécurité. Un modèle fermé, basé sur une API, implique que les bases de code, les documents ou les données métier doivent être traités via le cloud, ce qui peut compliquer l'adoption dans des secteurs sensibles à la confidentialité comme la finance et la santé.
Le second point concerne le rythme d'adaptation de l'écosystème et de la chaîne d'outils. Les modèles ouverts ont tendance à générer très rapidement des plugins communautaires, des variantes quantifiées, des flux de travail d'optimisation et des utilitaires tiers. Si la branche principale de Qwen 3.6 reste fermée, certains développeurs pourraient être moins enclins à investir dans la création d'outils externes et d'intégrations.
Une troisième interprétation, plus commerciale que technique, est possible. Certains observateurs du secteur y voient un signe de la stratégie de monétisation globale d'Alibaba Cloud : conserver ses modèles les plus performants au sein de sa propre plateforme cloud afin de renforcer l'adoption des services gérés, l'utilisation des API et les revenus de calcul associés.
Globalement, cela n'affaiblit pas nécessairement le produit lui-même. Toutefois, cela modifie les compromis. Pour les équipes utilisant déjà Alibaba Cloud, le modèle hébergé peut s'avérer pratique et économique. Pour celles qui privilégient l'auto-hébergement, la gouvernance ou une personnalisation poussée, le modèle de déploiement peut être presque aussi important que les résultats des tests de performance.
Qwen3.6-Plus Cette solution hébergée semble prometteuse pour les développeurs soucieux du contexte étendu, des flux de travail de codage et des tâches multimodales. Sa fiche technique officielle est solide, son prix est relativement compétitif pour les applications d'entrée de gamme, et les supports de lancement d'Alibaba la positionnent de manière crédible dans les catégories de benchmarks exigeantes en termes de performances. Toutefois, le déploiement en mode hébergé pourrait s'avérer pertinent pour les équipes privilégiant les modèles open source ou auto-hébergés.

