
El 4 de marzo de 2026, Google presentó oficialmente la última incorporación a la serie Gemini 3:Gemini 3.1 Flash-LiteDiseñado específicamente para cargas de trabajo de desarrollo de alta concurrencia e implementaciones a escala empresarial, este modelo está optimizado para maximizar la velocidad y la rentabilidad. Basado en un análisis de documentación técnica oficial y datos de evaluación de terceros, este informe describe el rendimiento principal del modelo, los costos y las métricas de aplicaciones reales.
Resultados de rendimiento y puntos de referencia básicos
Gemini 3.1 Flash-Lite ha demostrado una competitividad técnica significativa en varios puntos de referencia de IA convencionales. Según datos de Arena.ai tabla de clasificación, el modelo logró una calificación Elo de 1432. En el Diamante GPQA prueba, que mide el razonamiento a nivel experto, alcanzó una precisión de 86.9%, mientras anotaba 76.8% en el MMMU Pro Prueba de comprensión multimodal.
Los datos indican que las capacidades generales de Gemini 3.1 Flash-Lite no solo superan a otros modelos de su nivel, sino que también superan a los modelos más grandes de la generación anterior. Géminis 2.5 Flash En múltiples indicadores. Este salto de rendimiento permite a los desarrolladores lograr una mayor potencia de procesamiento lógico manteniendo un bajo consumo de recursos.
Panorama competitivo: comparación intergeneracional y entre pares
En el mercado de modelos pequeños de 2026, Gemini 3.1 Flash-Lite compite principalmente con GPT-5 mini y Haiku de Claude 4.5. Una comparación directa con su predecesor, Géminis 2.5 Flash, ilustra aún más su evolución técnica:
| Métrico | Gemini 3.1 Flash-Lite | Géminis 2.5 Flash | GPT-5 mini | Haiku de Claude 4.5 |
| Velocidad de salida | ~363-384 fichas/s | ~150-200 fichas/s | ~71 fichas/s | ~108 fichas/s |
| Tiempo hasta el primer token (TTFT) | Lo más rápido | Base | Más lento | Medio |
| Precio de salida (/1M) | $1.50 | $0.60 | $2.00 | $5.00 |
| Precisión de SimpleQA | 43.30% | 28.50% | 9.50% | 5.50% |
| Ventana de contexto | 1 millón de tokens | 1 millón de tokens | 400k tokens | 200k tokens |
Las métricas muestran que, si bien Gemini 3.1 Flash-Lite tiene un precio más alto que 2.5 Flash, su velocidad de salida ha aumentado aproximadamente 45% y el tiempo hasta el primer token (TTFT) se ha reducido a 40% de la línea base anterior.
La lógica de la relación coste-eficiencia: relación precio-complejidad del token
Si bien las discusiones de la comunidad han señalado el aumento de precio de la serie Gemini 3 Flash, centrarse únicamente en el precio unitario del token carece de contexto completo. La métrica fundamental para la selección del modelo es la relación entre el precio y la complejidad del token.
Por ejemplo, en otros modelos industriales, aunque Sonnet 5 puede tener un precio unitario más bajo, podría requerir una cantidad significativamente mayor de tokens que Opus 4.6 para lograr el mismo resultado en tareas complejas, lo que resulta en un mayor costo total real. La ventaja de Gemini 3.1 Flash-Lite reside en su densidad de información y eficiencia de ejecución por token. Para los desarrolladores, la elección de un modelo debe ir más allá de los puntos de referencia y los precios de los tokens; debe centrarse en si el modelo proporciona una mejora tangible al flujo de trabajo específico.
Comentarios de la comunidad y rendimiento visual en el mundo real
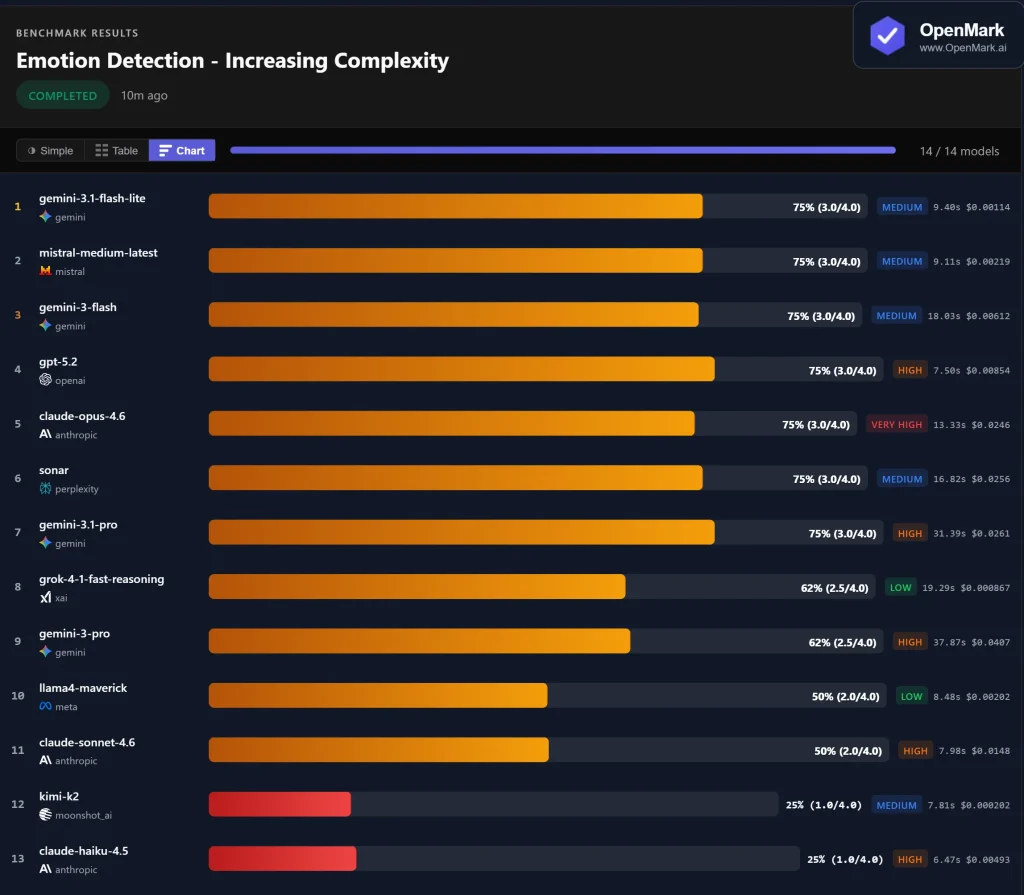
En aplicaciones prácticas, varios usuarios ya han implementado el modelo a gran escala. En una prueba de referencia visual para la detección de emociones humanas, involucrando 14 modelos grandesGemini 3 Flash obtuvo el primer puesto tras una evaluación exhaustiva de precisión, velocidad de respuesta y consumo de tokens. Este resultado confirma su estabilidad al gestionar entradas multimodales complejas.
Empresas pioneras como Latitude, Cartwheel y Whering informan que el modelo se mantiene estable en el procesamiento de contextos largos y el seguimiento de instrucciones. En el sector del comercio electrónico, se utiliza para generar paneles dinámicos basados en datos en tiempo real, mientras que en la industria SaaS, impulsa agentes inteligentes capaces de ejecutar tareas de varios pasos.
A pesar de sus fortalezas, la comunidad ha identificado ciertos desafíos. Gemini 3.1 Flash-Lite tiende a ser demasiado verboso, lo que puede resultar en un número de tokens de salida mayor al esperado en ciertos escenarios, incrementando así los costos. Además, la versión preliminar ha experimentado fluctuaciones de respuesta durante el uso máximo de la API, un factor que requerirá optimización técnica durante los lanzamientos comerciales a gran escala.

